はてなスター風のブログパーツを作るというミッション。今流行の、script タグではりつけたら、その場に表示されて、JSONP でサーバ側の SQLite に記録する、ていうものを考えて、一応できたんですけれども、貼られた script タグの位置を特定する仕組みがよくわからないのでDOM内の script を列挙して、src属性が スクリプト名とマッチしているかどうかで貼られた位置を特定する、という方法でお茶濁した。
そこらへんのノウハウが不足しているなー探してみよう。
はてなスター風のブログパーツを作るというミッション。今流行の、script タグではりつけたら、その場に表示されて、JSONP でサーバ側の SQLite に記録する、ていうものを考えて、一応できたんですけれども、貼られた script タグの位置を特定する仕組みがよくわからないのでDOM内の script を列挙して、src属性が スクリプト名とマッチしているかどうかで貼られた位置を特定する、という方法でお茶濁した。
そこらへんのノウハウが不足しているなー探してみよう。
業務で FC2 BLOG を使っているんですが、あの blog システム、画像 UP してすると、サムネイル幅が 160px になるんですよ。僕が取り扱っている blog は、本文が 350px 幅なので、160px のサムネイルはあんま使い道ねーなーて思っています。だって、160pxにすると、回り込み前提のデザインだということなんだけれども、それって単に回り込みレイアウトをしなきゃいけないという思いこみだったり、回り込みレイアウトにあこがれているとか、そういう理由なんじゃないのかな? そんなちっぽけな理由で、読み手にワンクリックを強要するわけですね。

かくいう僕は、この blog では、450px 幅までは等倍、450px超幅は 450px になるようにスクリーンショットを取っていますので、それに合わせてウィンドウサイズを変更したりして(MagnetWindow[3rdproject.mine.nu] っていうソフトで px 数確認してサイズ変更しています)、なんだか不自然なスクリーンショットになっているのが特徴です。そして、450px より大きいスクリーンショットだったら、等倍の画像にリンクする、ていうやり方。つまり僕自身が回り込み嫌いだからなのです。
▲このダイアログボックスの場合、422px 幅だったので等倍で表示
これとて、ありのままの姿を記録しなければならない、ていう一派に言わせると邪道っぽいですよね。
つうわけで、blog のサムネイルは、blog システムのお仕着せになりがちだ、ていう話題でしたとさ。そういや、ココログのデフォルトもサムネイル 100px だったような気がしてきた……
(CSS の max-width や max-height にあこがれた時期もありました……)
いま、ワープロ打ちを、SOTEC の 15.4 inch ワイド液晶のマシンでやっとるんですけれども、ワイド液晶ということで、視界が液晶で占められるので、結構作業にのめりこみやすいかも。
この前まで、12.1 inch のふつうの液晶のマシン使っていたけれども、この違いは大きいかも、て思いました。
ワイド液晶だと何気に InDesign も使いやすいよ!
友達の女の子が、日記風読み物を書いていて、これにカレンダーをつけたいんだよねーていうミッション。
最初は、
my $cal = `cal`;
とかしてお茶濁そうと思ったけれども、これ cal コマンド入っていないとだめで、Windows だとダメっぽげです。
つうわけで、
Calendar::Simple - シンプルなカレンダーを作る為のPerl拡張 [perldoc.jp]
をみて作ってみました。
#!/usr/bin/perl
use strict;
use warnings;
use CGI;
my $q = CGI->new();
my $year = $q->param('year' ) || (localtime)[5] + 1900;
my $month = $q->param('month') || (localtime)[4] + 1;
print $q->header( -type => 'text/html',
-charset => 'UTF-8',
);
print $q->start_html(
-lang => 'ja_JP',
-encoding => 'UTF-8',
),
$q->start_pre,
_calendar(
{ year => $year,
month => $month,
base_url => 'http://www.example.com/cgi-bin/foo.cgi',
}
),
$q->end_pre,
$q->end_html,
;
exit 1;
sub _calendar {
require Calendar::Simple;
my $param = shift;
my $year = $param->{year };
my $month = $param->{month };
my $url = $param->{base_url};
my $cal = Calendar::Simple::calendar( $month, $year );
my $tmp_cal;
foreach (@$cal) {
push @$tmp_cal,
join( ' ',
map {
$_
? sprintf "<a href=\"%s?date=%4d%02d%02d\">%2d</a>",
$url, $year, $month, $_, $_
: ' '
}
@$_
);
}
my $str_cal;
$str_cal .= "Su Mo Tu We Th Fr Sa\n";
$str_cal .= join("\n", @$tmp_cal);
$str_cal =~ s{\s+$}{}xmgo;
return $str_cal;
}
pre 要素で表示しているのは i-mode などで見ることを一応想定してみました。

▲僕の端末より画面が広いよ!
さて、作ってから判明したんですけれども、どうやら、彼女の作ってる日記風読み物、6月19日が2つあるんです。
どうしようw
Amazon から METAL GEAR SOLID COLLECTION が来た! 我が家では初めての PS2 ソフト! でも UMD ロゴまで入っているんですが! なにこれ! ねえよ!
あとこれ、いつプレイするんだろうねー
仲いいね。
TypePad ASP サービス [www.sixapart.jp] を利用しているサイトのドメインを nslookup すると結構おもろいかも。
Photoshop CS3 を終了しなけりゃいいのね。ずうっとサスペンドしてたから余裕で30日越えてた!
# 今シリアルナンバー入れた
DTP+営業メモ - 我々は萌えているか?次世代萌え会議in大阪 [d.hatena.ne.jp] より。
JaGra っていうと、社団法人日本グラフィックサービス工業会 [www.jagra.or.jp] ていうやつで、これが、業界のための動画放送サイト、ジャグラ BB つうのを立ち上げているんですけれども、まあ印刷業界の人でさえ認知度低いのに、一般的にどうだっていうのを話すのは酷ですよね、まあそんな動画サイトです。印刷会社の取材撮影などもしてまして、スゲーがんばっているって言う印象だけれども、ターゲット狭すぎるので、ニッチの中のニッチを行っている印象も否めません。
ジャグラBB - 印刷業のためのWebラーニングサイト:徹底闘論 我々は萌えているか?次世代萌え会議in大阪【前編】 [www.jagra.or.jp]
wktk してサンプル見てみました!

……このサンプル、萌え要素なんて一滴もないんですけれども!
だまされた!
(社長萌えとか言うなよ)
本当の萌えを知っている諸兄にぶっつぶしていただきたいと思いました。

ジャグラBB 見られる方、最後まで見てどの辺が萌えだったか教えてくだちい!
OCFとQuarkXPress 3.3 - lcs_kawamuraの開発記録 - Yahoo!ジオシティーズ [geocities.yahoo.co.jp]
6月1日付けで、大日本印刷市ヶ谷事業部から、OCF並びにQuarkXPress 3.3での入稿を本年末で終了する旨の文書が出ている。環境の維持が困難であり、OCFはCIDフォントに、QuarkXPress 3.3は4.1に置き換えて作業するという。文字ずれなどの可能性があり、出校物の確認をお願いしている。これを受けて出版社も同様の対応を、制作会社に求め始めている。
(文中の6月1日とは、2007年のことです)
うちの顧客は全くDNP の出版とかぶらないので、この業界全体をみると、DNP がイニシアチブとってやっている業界ではないとは思うけれども、「てんかのでぃーえぬぴーのおふれだから」これみて右ならえ指示出しちゃう偉い人もいそうですよね。
このはなしって、旧 Mac OS 用 モリサワ New-CID フォントと、旧 Mac OS 用 QuarkXPress 4.1J が現行製品だから、それ買ってやれば最小限の学習コストで済みますよね。かつて 新規版で ¥282450 した QuarkXPress 4.1J は、いま新規でも ¥80850 ですし。

ただ、問題は、QuarkXPress 4.1J の、びみょーなバグ、いまから 3.3J→4.1J に移行しようとする人はどうやって気付くか、ていう話かもしれないですね。
ネットでは 3.3J → 4.1J の移行はとうの昔に終わった話とされているから、どうやって 4.1J 安定環境構築の情報にキャッチアップできるんだろうね。
つうわけで、QuarkXPress 3.3J + モリサワ OCF のシステムが、道具としてしっくりしてほかに移行したくない人は、この環境で PDF を作って入稿する方法を模索すればいいんだと思いました。
~~~
InDesign が選択肢だって言える人は指先の資産を反故にできる勇気のある強い人だと思う、それを他人に言うのは強者の理論だよねーて思うときはあります。
メールアドレスの登録・解除を簡単に行える Web アプリを作るミッション。
そんで、簡単に、ていうことは、メールアドレスだけ入れて Submit すりゃいいんだろうけれども、最近の Web はロボットが穴(input 要素)があったら突っ込んでくる物騒な世界ですので、しょうがないから CAPTCHA 入れなきゃねーということになって、Authen::Captcha ていう Perl モジュールを入れようと思ったんだけれども、こいつは GD に依存していて、CentOS 4.4 から CPAN で GD を入れようとしたらダメでした。
つうわけで、調べてみたら、
RPMforge を yum のリポジトリに追加することによって、Perl 関係のモジュールが rpm になった状態のものがオンラインでゲットできるんだそうです。
CentOS で構築する自宅サーバ : yum に RPMforge リポジトリを追加する [centos.oss.sc]
を参考にして、yum に RPMforge のリポジトリを追加して、Perl-GD を入れることができました。
その後、CPAN から Authen::Captcha もインストールできたので、目的のものはマッハでできてしまいました。
いままで、CPAN から落としてもうまく入らないものがあったけれども、これでいくつかは解消されるのかもしれません。
InDesign居残り補習室 フリープラグインが出ていた [kstation2.blog10.fc2.com]
で、新しいプラグインが発表されている。 “RemoveLM”というフリープラグインだ。
とのことで、
M.C.P.C.: レイアウトソフトにおけるプラグイン使用で悶々
というエントリで取り上げた、InDesign の勉強部屋 BBS で問題になっていた、プラグインを使用したInDesignデータの、プラグイン固有情報が残っていると、プラグインがない環境で問題を起こす、という件において、プラグイン開発側からの対応策が提示されたことになります。
提供されている圧縮ファイルの内容を読みますと、
RemoveLM.pdf :
RemoveLMにより、LineMarker Plug-inにより文書に付加されるPlug-in情報を削除すると、LineMarkerが入っていないInDesignで開いても、アラートが表示されなくなります。LineMarkerで文字に付加された、網かけ属性は維持されます。
ということで、削除されるのは、Plug-in 情報であることに注意しなくてはならないようです。
網掛け処理の属性を完全に消去するには、
RemoveLM.pdf :
LineMarkerによりInDesign文書及び文字に付加された固有の情報を完全に削除するには、LineMarkerが入っていないInDesignで開き、InDesign互換形式で書き出し、INX形式ファイルを開いて、保存し直して下さい。
InDesign 2.0、CSでは、文書を開く時に表示されるアラートで、「失われたプラグインデータをドキュメントから削除」を実行すると、LineMarker固有の情報を削除することができます。
とありますが、網掛け属性が消去されたときに、ドキュメントの網掛け部がどう表現されるのか、という情報が、プラグインを使ったことがない人にはわからないところです。
プラグインを使ったことがない出力業者としては、クリーンなデータを入稿してほしいですから、
というプロセスを踏むとすると、3の時点で、ドキュメントがどのような状態になるか提示されていないのが不安材料です。
実際に使っている方に教えていただくのが一番でしょうが、プラグインベンダからの情報がそこまでフォローが入っていたらなあと思いました。いつも少ない情報で判断&指示みたいなバクチになるのは嫌ですよー
開発者の方の blog に Trackback しようかと思ったのですが、Trackback URL がありませんので、リンクを張っておきます。
RemoveLM - lcs_kawamuraの開発記録 - Yahoo!ジオシティーズ [geocities.yahoo.co.jp]
[226197]非 PostScript からの印刷時のトラブルシューティング(Illustrator CS2) [support.adobe.co.jp]
A. トラブルシューティング
A-1. プリンタドライバのアップデートまたは再インストール
A-2. [ビットマッププリント] オプション(Windows)
A-3. エンハンスド PCL(Windows)
A-4. 標準ビデオカードドライバ(Windows)
A-5. テキスト形式の変更
A-6. 隠れたカラーオブジェクトを追加します
A-7. [プリントするレイヤー] オプション
A-8. 通常使うプリンタの設定(Windows)
A-9. ローカルプリンタに出力します
(太字は僕が付けた)
意味がわかりません、ていうかわかりたくねえ。Windows のGDI プリンタ(PCL プリンタ)で変なプリントアウトでたときはとりあえずビットマッププリント、って言う経験則は、あながち間違っていなかったんだといえそうです。
http://blog.dtpwiki.jp/dtp/2007/07/adoberss_358b.html#comments
いつも拝見しています。
ところで駆け込み寺のRSSって死んでます?
投稿者: かたやなぎ (2007/07/19 9:20:11)
ところで駆け込み寺のRSSって死んでます?
はい、さっきまで死んでました、ていうか、
M.C.P.C.: DTP駆け込み寺スレッド表示モードでモダンブラウザでトピックリンクがきかない件直してもらいました。
のエントリで、掲示板メンテナーさんに不具合直してもらったときに入った修正箇所を、RSS 生成側で抽出キーワードとして使っていたんですね。全く面目ないです。
今は直っていますので、ご利用いただけます。ご指摘ありがとうございました。
つうわけで、ソース。結構古いソースやな。
#!/usr/bin/perl -w
use strict;
use LWP;
use XML::RSS;
use HTML::Entities;
use utf8;
use Encode;
my $url = 'http://gande.co.jp/cgi-momoco/2chview.cgi';
my @headers = (
'User-Agent' => 'DTPWiki.jp html2RSSbot'
. ' (http://dtpwiki.jp/rss/'
. 'dtpkakekomidera.xml)',
);
my $browser = LWP::UserAgent->new;
my $response = $browser->get($url, @headers);
exit 1 unless $response->is_success;
my $html = decode('cp932',$response->content);
$html =~ s/\x0D\x0A|\x0D|\x0A/\n/g;
$html =~ s|^.+次のページ</a>\n\t</div>\n</div>\n\n||sgo;
$html =~ s|\n\n<div class="linkmenu">.+$||sgo;
$html =~ s|\t|<tab />|g;
$html =~ tr/\x00-\x1f//d;
$html =~ s|<tab />|\t|g;
my $rss = XML::RSS->new;
$rss->add_module(
prefix=>'content',
uri=>'http://purl.org/rss/1.0/modules/content/',
);
$rss->add_module(
prefix=>'annotate',
uri=>'http://purl.org/rss/1.0/modules/annotate/',
);
$rss->channel(
title => 'DTP駆け込み寺 掲示板',
link => 'http://gande.co.jp/cgi-momoco/momoco.cgi?btype=pc&page=1',
description => 'DTP駆け込み寺 掲示板 最新書き込み(50件)',
language => 'ja',
dc => {
publisher => 'DTP駆け込み寺',
contributor => 'DTPWiki.jp',
},
syn => {
updatePeriod => 'hourly',
updateFrequency => '1',
},
);
my ($filesize,$link,$date,$title,$description,$platform);
my (%item,@items);
(my $Regex = <<'REGEX') =~ tr/\n//d;
<div class="comment">
\t<h4><a id="t_(..............)">(.+?)</a></h4>
\t<p>名前:<strong>(.+?)</strong>............
<span class="small"> \[(.+?)\]</span><br>
\t(.+?)
\t</p>\t(.+?)</div class="comment">
REGEX
my $i;
$html =~ s|</div><div class="comment">|</div class="comment"><div class="comment">|g;
$html =~ s|</div>$|</div class="comment">|;
while($html =~ m|$Regex|gsio) {
my $link = $1;
my $title = $2;
my $name = $3;
my $ua = $4;
my $description = $5;
my $html2 = $6;
$name =~ s|<a href=".+?">(.+?)</a>|$1|;
$ua = normalize2( $ua );
$date = datecheck2($link);
push @items ,{
title => normalize2("$title"),
description => normalize2("$description --$name\[$ua\]"),
link => "http://gande.co.jp/cgi-momoco/momoco.cgi?btype=pc&mode=tp&ord=new&page=1&file=$link",
date => $date,
creator => normalize2($name),
content => "<![CDATA[<p>$description</p><p>$name\[$ua\]</p>]]>",
annotate => '',
};
# (my $year = $link) =~ s|(....).*|$1|;
(my $Regex2 = <<'REGEX') =~ tr/\n//d;
<hr>
\t<p>(...) 名前:<strong>(.+?)</strong> (../.. ..:..)
<span class="small"> \[(.+?)\]</span><br>
\t(.+?)\t</p>
REGEX
my $date_before = $date;
while ($html2 =~ m/$Regex2/gsio) {
# $i++;
# print "$i $3\n";
my $number = $1;
$name = $2;
$date = $3;
$ua = $4;
$description = $5;
(my $year = $date_before) =~ s|(....).*|$1|;
my $date2 = "$year-$date:00";
$date2 =~ s|(..) (..)|$1T$2|;
$date2 = datecheck($date2);
if ($date2 lt $date_before) {
$year++;
$date2 = "$year-$date:00";
$date2 =~ s|(..) (..)|$1T$2|;
$date2 = datecheck($date2);
}
$date_before = $date2;
$name =~ s|<a href=".+?">(.+?)</a>|$1|;
$ua = normalize2( $ua );
push @items ,{
title => normalize2("re\[$number\]:$title"),
description => normalize2("$description --$name\[$ua\]"),
link => "http://gande.co.jp/cgi-momoco/"
. "momoco.cgi?btype=pc&mode=tp&ord=new"
. "&page=1&file=$link#$number",
date => $date2,
creator => normalize2($name),
content => "<![CDATA[<p>$description</p><p>$name\[$ua\]</p>]]>",
annotate => "http://gande.co.jp/cgi-momoco/momoco.cgi"
. "?btype=pc&mode=tp&ord=new&page=1&file=$link",
}
}
}
#exit;
my @sort = sort { $b->{date} cmp $a->{date} } @items;
splice (@sort, 50);
#my $i;
foreach my $item (@sort) {
#$i++;
#print "$i\n";
$description = $item->{'description'};
if ($item->{'annotate'} eq '') {
$rss->add_item(
link => $item->{'link'},
title => $item->{'title'},
description => $item->{'description'},
dc => {
date => $item->{'date'},
creator => $item->{'creator'},
},
content => {
encoded => $item->{'content'},
},
);
}
else {
$rss->add_item(
link => $item->{'link'},
title => $item->{'title'},
description => $item->{'description'},
dc => {
date => $item->{'date'},
creator => $item->{'creator'},
},
content => {
encoded => $item->{'content'},
},
annotate => {
reference => $item->{'annotate'},
},
);
}
}
#splice (@{$rss->{'items'}}, 50);
if ($ENV{GATEWAY_INTERFACE}) {
require CGI;
print CGI::header(
-type => 'text/xml',
-charset => 'utf-8',
);
}
print encode('utf8', $rss->as_string() );
sub normalize {
local $_ = shift;
tr/ \r\n//d;
return $_;
}
sub normalize2 {
local $_ = shift;
tr|\x00-\x1f ||d;
s/<(?:[^>'"]*|(['"]).*?\1)*>//gs;
return $_;
}
sub datecheck {
local $_ = shift;
tr#/#-#d;
s/\(.+\) /T/g;
s/^: //g;
s/$/+09:00/g;
return $_;
}
sub datecheck2 {
local $_ = shift;
s/^(....)(..)(..)(..)(..)(..)/$1-$2-$3*$4:$5:$6+09:00/;
tr/*/T/;
return $_;
}
http://dtpwiki.jp/rss/adobejpproductupdate.xml
で、
アドビ - 製品のアップデート [www.adobe.com]
を RSS に変換したものを取れるようにしました。
つまり、

▲「アドビ - 製品のアップデート」のページをブラウザで表示
の内容を、RSSリーダで読めます。
次の画像は、Opera 内蔵のメールソフト、M2 で見た場合です。

▲Opera M2 で RSS 表示
対象 RSS がアップデートされたら項目が追加される様はまるでメールソフトみたいです。Mozilla Thunderbird に RSS を登録するっていうのもお勧め。
~~~
生成スクリプトのソースです。
#!/usr/bin/perl
use strict;
use warnings;
use LWP;
use XML::RSS;
use HTML::Entities;
use utf8;
use Encode;
binmode STDOUT => ":utf8";
use HTML::TreeBuilder;
my $base_url = 'http://www.adobe.com';
my $url = 'http://www.adobe.com/jp/downloads/updates/';
my @headers = (
'User-Agent' => 'DTPWiki.jp html2RSSbot('
. 'http://dtpwiki.jp/rss/'
. 'adobejpproductupdate.xml)',
);
my $browser = LWP::UserAgent->new;
my $response = $browser->get($url, @headers);
exit 1 unless $response->is_success;
my $html = decode('utf8',$response->content);
$html =~ s/\x0D\x0A|\x0D|\x0A/\n/g;
$html =~ tr/\t//d;
$html =~ s|src="|src="$base_url|g;
(my $Regex = <<'REGEX') =~ tr/\n//d;
<h4>(.+?)</h4>.+?<p>(.+?)<br\s/>\s*(.+?)</p>
REGEX
my $data;
{
my $item;
while ($html =~m|$Regex|xgsio) {
$item = { title => $1,
date => parse_date($2),
description => $3,
url => q(),
};
my $tree = HTML::TreeBuilder->new();
$tree->parse($item->{description});
$tree->eof();
if (my $a = $tree->find('a') ) {
$item->{url } = $a->attr_get_i('href');
}
$tree->delete;
$tree = HTML::TreeBuilder->new();
$tree->parse($item->{title});
$tree->eof();
if (my $a = $tree->find('a') ) {
$item->{title} = $a->as_text;
$item->{url } = $a->attr_get_i('href');
}
$tree->delete;
push @$data, {
title => $item->{title},
link => $base_url . $item->{url},
date => $item->{date },
description => $item->{description},
};
}
}
my $sort;
@$sort = sort { $b->{date} cmp $a->{date} } @$data;
my $rss = XML::RSS->new;
$rss->add_module(
prefix=>'content',
uri=>'http://purl.org/rss/1.0/modules/content/'
);
$rss->channel(
title => 'アドビ - 製品のアップデート',
link => $url,
description => 'アドビ - 製品のアップデート',
language => 'ja',
dc => {
publisher => 'adobe.com/jp',
contributor => 'DTPWiki.jp',
},
syn => {
updatePeriod => 'weekry',
updateFrequency => '1',
},
);
foreach my $item (@$sort) {
my $description = $item->{'description'};
$rss->add_item(
link => $item->{'link'},
title => $item->{'title'},
description => encode_entities($description, '<>&"'),
dc => {
date => $item->{'date'},
},
content => {
encoded => '<![CDATA['
. $description
. ']]>',
},
);
}
if ($ENV{GATEWAY_INTERFACE}) {
require CGI;
print CGI::header('text/xml; charset=utf-8');
}
print $rss->as_string();
exit 1;
sub parse_date {
my $date = shift;
$date =~tr|0-9|0-9|;
$date =~tr|年月|--|;
$date =~tr|日||d;
(my $year, my $mon, my $day) = split('-', $date);
return sprintf("%04d-%02d-%02d", $year, $mon, $day );
}
以前のものよりもすっきりしていますが、これは以前のダウンロードページは、HTML の更新作業をものすごく手作業でやっていたらしく、HTML の構造がキメラで、個別対応部分がすごいぐちゃぐちゃしていたからです。
(2008-10-6 11:45追記)
Adobeのダウンロードの更新情報のRSSフィードを勝手に作成しました - diary@longkey1.net
にて、高機能版のRSSが公開されています。
ちょっと用事がありまして、災害用ブロードバンド掲示板 [www.web171.jp] を使ってみました。
▲災害用ブロードバンド掲示板(blog用に、縮小表示しています)
これが微妙に使いにくい。
以下キャプチャで。
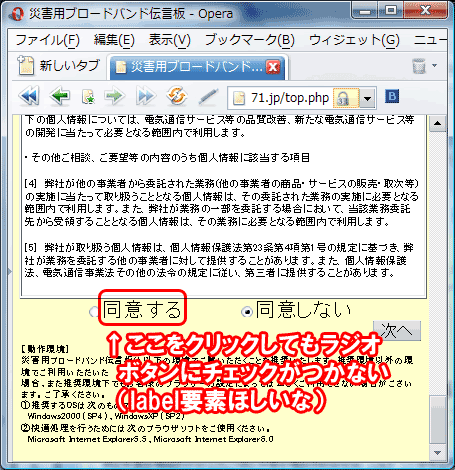
▲こんな小さいぽっちクリックさせるのかよ
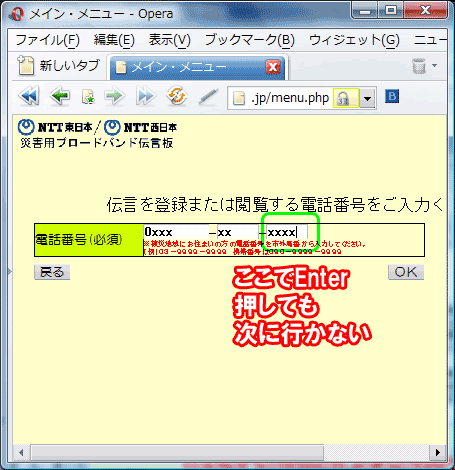
▲Enter で Submit できなくしている意味がわからない
CSS Nite とか出た人の誰かが直してくれないかな。
一番の罠は、トップページの URL が、https://www.web171.jp と、SSL ページになっていることです。URL を覚えたつもりでも、http として入力しちゃうんですよね。つながりません。なぜ? テレビCM でも URL 表示は一瞬なので、絶対 https を見逃すって。
http://www.adobe.com/jp/support/downloads/new.html
のページを RSS 化している、
adobe.com/jp - Downloadable Files
http://dtpwiki.jp/rss/adobecojpnewdownloads.xml
が、更新とまっとる。おそらく、アドビに廃棄されたんだと思われ。
こんなコードで生成していました。
#!/usr/bin/perl -w
use strict;
use LWP;
use XML::RSS;
use HTML::Entities;
use utf8;
use Encode;
my $url = 'http://www.adobe.com/jp/support/downloads/new.html';
my @headers = (
'User-Agent' => 'DTPWiki.jp html2RSSbot(http://dtpwiki.jp/rss/adobecojpnewdownloads.xml)',
);
my $browser = LWP::UserAgent->new;
my $response = $browser->get($url, @headers);
exit 1 unless $response->is_success;
my $html = decode('UTF-8',$response->content);
$html =~ s/\x0D\x0A|\x0D|\x0A/\n/g;
my $rss = XML::RSS->new;
$rss->add_module(
prefix=>'content',
uri=>'http://purl.org/rss/1.0/modules/content/'
);
$rss->channel(
title => 'adobe.com/jp - Downloadable Files',
link => $url,
description => 'adobe.com/jp - Downloadable Files',
language => 'ja',
dc => {
publisher => 'adobe.com/jp',
contributor => 'DTPWiki.jp',
},
syn => {
updatePeriod => 'weekry',
updateFrequency => '1',
},
);
my ($filesize,$link,$date,$title,$description,$platform);
my (%item,@items);
$html =~ s|.+?<!--TABLE-->||s;
$html =~ s|<div id="globalfooter">.+?||s;
$html =~ s|\n||g;
$html =~ s|> +?<|><|g;
$html =~ s|<!-- rowstart:spacer5 -->||g;
$html =~ s|<!-- rowend:spacer5 -->||g;
$html =~ s|<!-- rowstart:interline -->||g;
$html =~ s|<!-- rowend:interline -->||g;
$html =~ s|<!-- rowstart:content -->||g;
$html =~ s|<!-- rowend:content -->||g;
$html =~ s|<!-- rowstart:border -->||g;
$html =~ s|<!-- rowend:border -->||g;
$html =~ s|<!-- rowstart:spacer15 -->||g;
$html =~ s|<!-- rowend:spacer15 -->||g;
$html =~ s| width="585">|>|g;
$html =~ s|colspan="7" height="30" nowrap="NOWRAP">|colspan="7" height="30">|g;
$html =~ s|<td bgcolor="#cccccc" class="size2" colspan="7" height="30"><a href="(.+?)"><strong>(.+?)</strong></a></td>|<td bgcolor="#cccccc" class="size2" colspan="7" height="30"><strong><a href="$1">$2</a></strong></td>|g;
$html =~ s|<td bgcolor="#cccccc" class="size2" colspan="." height="30">|<!-- separator --><td bgcolor="#cccccc" class="size2" colspan="7" height="30">|g;
$html =~ s|<a class="size1" href="|<a href="|g;
$html =~ s|<td align="right" class="size1" width="100"></td><td width="15"></td>||;
$html =~ s|$|<!-- separator -->|;
#print $html;
#exit;
(my $Regex = <<'REGEX') =~ tr/\n//d;
<td align="right" class="size1" width="100">(.+?)</td>.*?
<td class="size1" width="350"><a.+?href="(.+?)".*?>(.+?)</a>.*?
<td class="size1" width="70">(.+?)</td>
REGEX
my $i;
while($html =~ m|<td bgcolor="#cccccc" class="size2" colspan="." height="30"><strong><a.+?>(.+?)</a>(.+?)<!-- separator -->|gsio) {
my $category = $1;
my $html2 = $2;
$platform = '[Mac]' if ($category =~ m/Mac/);
$platform = '[Win]' if ($category =~ m/Win/);
while ($html2 =~ m/$Regex/gsi) {
$date = $1;
$link = $2;
$title = $3;
$filesize =$4;
my $date2 = "20$date";
$link = "/jp/support/downloads/$link" unless ($link =~m|/|);
$platform = '[Mac]' if ($link =~ m/mac/);
$platform = '[Win]' if ($link =~ m/win/);
push @items ,{
title => normalize2("$platform$title"),
description => normalize("[$date] $title ($filesize)"),
link => encode_entities("http://www.adobe.com$link"),
date => datecheck($date),
content => "<![CDATA[$description]]>"
}
}
}
my @sort = sort { $b->{date} cmp $a->{date} } @items;
foreach my $item (@sort) {
$description = $item->{'description'};
$rss->add_item(
link => $item->{'link'},
title => $item->{'title'},
description => $description,
dc => {
date => $item->{'date'},
},
content => {
encoded => "<![CDATA[$description]]>",
},
);
}
if ($ENV{GATEWAY_INTERFACE}) {
require CGI;
print CGI::header('text/xml; charset=utf-8');
}
print $rss->as_string();
sub normalize {
local $_ = shift;
tr/ \r\n//d;
return $_;
}
sub normalize2 {
local $_ = shift;
tr/ \r\n//d;
s/<(?:[^>'"]*|(['"]).*?\1)*>//gs;
return $_;
}
sub datecheck {
local $_ = shift;
tr#/#-#d;
s/^/20/;
return $_;
}
ちなみに、今はこっちみたい。
http://www.adobe.com/jp/downloads/updates/
そのうち直します。
地震があると、毎回石灯籠の下敷きになるっていう事故が起こるんだけれども、源平討魔伝でもないかぎり石灯籠はハザードだからなんとかしたほうがいいと思う。
こんな台風の日にバーベキューをやるなんて。
お昼11時半から今まで12時間焼きっぱなし&飲みっぱなし。さすが地元の人はお酒強いなー
Illustrator CS/CS2 の重大な不具合として、ラスター EPS 画像をリンクで配置したデータを、PDF として書き出すと、一定間隔で細切れになってしまうというという問題があるのは、この blog でかなり前から取り上げておりまして(文末の参考リンク参照)、この制限に引っ掛かるデータというのは、最近の PDF 入稿機運の高まりで、既存 Illustator 8 データを CS2 で開いて、PDF/X-1a 保存して入稿する、みたいなシチュエーションで必ず出来てしまい、僕も印刷屋さん側として、逐次「Illustrator CS1/CS2 においては、EPS 画像は手作業で埋め込みをしてから PDF 保存をしていただくことになります。」とアナウンスしており、これが結構頻繁なので、アドビからサポート代行料を取りたい気分になるわけですけれども、そんなこというと、アドビの窓口の人が、「でしたらこちらで弊社製品の不具合については承りますので、苦情がございましたらアドビのほうにお取次いただきますよう」なんていうんだろうけれども、これで解決する問題じゃあねえと思うんです。よっぽど嫌われたんだな、僕。
それで、Illustrator CS3 では、EPS 画像リンクの PDF 保存の塩梅がどうなっているか、ていうのを調べました。
~~~
準備として、Illustrator CS2 と CS3 で、同じようにデータを用意しました。

▲Windows XP上のIllustrator CS2で制作

▲Windows Vista上のIllustrator CS3で制作

▲使用した・出来たファイル群
~~~
それでは、データのコマ切れを確認するため、Acrobat 8 の TouchUp オブジェクトツールで全選択、をしてみましょう。
まず、従来の Illsutrator CS2。

▲これがいわゆる細切れ問題。RIPが悪いと刷版に出て印刷事故
これをみると、この問題のためにすりなおしになった分の紙の怨念とか、クビになった人の怨念とか、見えるようです。
つぎ、Illustrator CS3。

▲細切れになっていない。安心して刷版が出せそう。年金が出るまで働けそうです
これによると、Illustrator CS3 で EPS リンク画像がある書類を PDF 保存したときは、細切れにならないようです。これで安心して仕事ができます。
~~~
インターネットの掲示板などで、「Illustrator CS 以降は、EPS は埋め込みましょう。常識です」みたいな書き込みを目にすると、非常にもにょる感覚に襲われました。というのは、この不具合は、どう考えても、Adobe Systems がソフトに織り込んでしまった不具合で、ユーザに不都合を生じさせ、プログラムの修正も大変ではないと思われたからです(手で埋め込んでいけば問題ないわけですから、完全に PDF 保存プロセスで、埋め込みの部分がおかしくなっているんだと認識していました)。
常識です、て言って思考停止するのではなく、不具合であるから直すような方向性に持っていけないでしょうか。
今回、Illustrator CS3 では、表題のとおり直ったようです、これは、僕が blog エントリを書いたからではなくて、Adobe Systems の中の人が、「これは修正すべき事象だ」と判断したから直ったにすぎません。しかし、問題点を「しょうがない」とかいって、不満をウチにためておくのではなくて、こういう問題があるんだわー何とかならんかなーて言うのをオモテに出しとかんと、伝わるものも伝わらんですよね。
日本のアドビシステムズさんは、こういう不具合がある時の報告プロセスを、もっと明確にして、製品の改善をしていってほしいものです。グラフィック製品の市場を独占した企業なのですから、株主のために製品発売しているんだよーとか言わずに、ユーザの方も見ているんだよーていうのをもうちょっとアピールしてもらえるといいかな。
参考リンク:
M.C.P.C.: TrueflowでIllustratorCSeps画像リンクPDFバンド状問題は問題ないのかしら [blog.dtpwiki.jp]
M.C.P.C.: 秋葉館にMac mini(PPC)用1GBメモリ発注 [blog.dtpwiki.jp]
ていうエントリで発注した、秋葉館の
秋葉館オンラインショップ-DDR SDRAM PC3200 1GB(1024MB) Hynix純正 [184-1024MS3200 GH] [www.akibakan.com]
を、Mac mini PPC に入れましたが、平気で動いています、やったね!
うちの Mac mini の場合、メモリスロットが 1 スロットなので、とりあえずメモリはここまでです。
OS 起動時で物理メモリ使用が 230MB 程度使用と表示されますから、デフォルトのメモリ 256MB では、よっぽどカツカツだったんですね。
ムービーメーカーをつかってニコニコにアップするっていう案件。
その子は Windows XP なのだけれども、すぐフリーズするっていうんで、僕の Vista だとフリーズしないよ? ていうことで、僕の XP でムービーメーカー起動して作業したらほどなく落ちた。ワラタ。
その後、普通に「Windows ムービーメーカー フリーズ」と検索したら死ぬほど出てきて泣けた。
DTP駆け込み寺 [www.dtptemple.jp] といえば、
以前、
M.C.P.C.: DTP駆け込み寺の「匿名」hidden+上部リンク部から記事に飛べるようにするGreasemonkeyスクリプト
で取り上げたとおり、モダンブラウザで使用時、スレッド表示モード(別名2ちゃん表示モード)で、上部に表示されるトピック一覧(スレッド一覧)をクリックしても、該当トピック(スレッド)を表示できないという問題がございまして、Greasemonkey スクリプトとかつくって対処していたのですけれども(どれだけの人が Greasemonkey とか使っていたかは疑問)、このたび、
掲示板メンテナーさんが
DTP駆け込み寺の掲示板:メールの設定 [gande.co.jp]
の21番に登場されたので、思い切って、不具合改善要望のトピックを立てました。
DTP駆け込み寺の掲示板:掲示板メンテナー様へ要望 [gande.co.jp]
そしたら、
001 名前:掲示板メンテナー 07/11 00:44 [Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)]
スレッド表示にて、ご指摘の件、修正しておきました。
ちなみにCGIがぶっ壊れていたわけでは無く、CGIによって生成されたhtmlが、html規約に則っていなかったのが原因です。(CGI作成者のコーディングミスです。)
以上、宜しく御願いします。
と、対応していただけました。
運営側の人があまりにも放置しまくるので半ば失望していましたが、今回対応していただけた件で、オラなんだかワクワクしてきました! げ~ん~き~だ~ま~SPARKING!
(補足)このエントリで取り上げた、LineMaker の問題に対応した解決法が提示されています。このエントリの文末を参照
InD-BOARD:L.C.S「LineMaker」バグ [cgi.www5c.biglobe.ne.jp] (直リン禁止なので
http://cgi.www5c.biglobe.ne.jp/~thats/study_bbs/study.cgi?mode=find&word=11764をコピーしてブラウザのロケーション欄に入れてください)
InDesign CS2をMac OS X 10.4.10で使っています。
L.C.Sという会社の「LineMaker」というプラグインを使っていましたが、特に使わなくなりましたので、プラグイン設定から外しました。
そしたら、いままで作成したドキュメントを開くと「LineMaker」がないというダイアログが出るようになってしまいました。おまけにドキュメントの保存時に上書きするかどうかと訊かれてしまいます。
さらにいままで作成したドキュメントはパッケージが「不明なエラー」で止まってします。ちゃんとパッケージできなくなってしまいした。
またプラグイン設定を元に戻せばいいのでしょうけれど、データ納品しなければならないものもあり困っています。
L.C.Sのホームページにはこうしたことは一言も書かれていませんでした。
ひどい話だとおもいます。
きちんとデータを元に戻す方法はありますか?
別名保存しても、やはりパッケージはできません。
を受けて、L.C.S さんから発行された文書
LineMarkerについての注意事項 [www.loyal.co.jp]
LineMarkerはInDesign上で、文字への網かけ処理を行うPlug-inですが、このPlug-inを使用すると、InDesign文書及び文字に、固有の情報が付加されます。このためLineMarkerは別Plug-inとして提供しています。
LineMarkerで付加した網かけをLineMarkerをお持ちでない環境で表示したり、プリントするツールとして無償のLineMarkerのランタイム版を提供しております。
LineMarkerを入れているInDesignで処理した文書を、LineMarkerが入っていないInDesignで開くと、環境に無いPlug-inとしてアラートが表示されます。付加された網かけに気付かずにそのまま処理をされることを避けるため、このアラートが出るようにしてあります。
LineMarkerが入っていないInDesignでそのまま開いて処理はできますが、InDesign文書及び文字に付加された固有の情報はそのまま残ります。また、パッケージ化すると異常終了することがあります。
InDesign文書及び文字に付加された固有の情報を削除するには、LineMarkerが入っていないInDesignで開き、InDesign互換形式で書き出し、INX形式ファイルを開いて、保存し直して下さい。
それで、傍観していた僕の感想
作業者の立場として、このような、処理後もプラグインやそのランタイムライブラリが必要なタイプのプラグインを使用したデータで一番困るのは、後年になって、過去データを編集しなくてはならなくなったときに、どのファイルが該当プラグインを使っていたかどうか、一つ一つ開かないと判明しないことだと思います。判明してしまったら、DTP な人おなじみのデジタル土方仕事で、チクチク片付けていくことはできるんで、InDesign 起動しなくても、判別できる方法があればなーて思いました。InDesign互換形式(.INX)書き出しで問題が解消されるとなると、.INX を書き出しして Perl とかで中身をチェックするという方法は採れないっつーことですよね。
(2007-07-20 17.45追記)
InDesign居残り補習室 フリープラグインが出ていた [kstation2.blog10.fc2.com]
で、新しいプラグインが発表されている。 “RemoveLM”というフリープラグインだ。
とのことで、プラグイン開発側からの対応策が提示されたことになります。
提供されている圧縮ファイルの内容を読みますと、
RemoveLMにより、LineMarker Plug-inにより文書に付加されるPlug-in情報を削除すると、LineMarkerが入っていないInDesignで開いても、アラートが表示されなくなります。LineMarkerで文字に付加された、網かけ属性は維持されます。
ということで、削除されるのは、Plug-in 情報であることに注意しなくてはならないようです。
網掛け処理の属性を完全に消去するには、
LineMarkerによりInDesign文書及び文字に付加された固有の情報を完全に削除するには、 LineMarkerが入っていないInDesignで開き、InDesign互換形式で書き出し、INX形式ファイルを開 いて、保存し直して下さい。
InDesign 2.0、CSでは、文書を開く時に表示されるアラートで、「失われたプラグインデータをド キュメントから削除」を実行すると、LineMarker固有の情報を削除することができます。
とありますが、網掛け属性が消去されたときに、ドキュメントの網掛け部がどう表現されるのか、という情報が、プラグインを使ったことがない人にはわからないところです。
(2007-07-20 19.24追記)
M.C.P.C.: InDesign用文字網掛けLineMarkerプラグインで入る固有情報を除去するプラグインRemoveLMが出たが出力業者としてどうすればいいかわからない
紀伊國屋書店に行ったら、こんな本を売ってました。

Windows Vista のガジェットって、HTML と JavaScript で動いとるので、AJAX でがりがりやっている人なら簡単にガジェットができるのですね。
これ買ってきて、さて、Trueflow のサーバの容量を監視するガジェットでも作ろうかなー(昔ひどい目にあった)、と思い、プログラミングしようと思ったのですけれども、よく考えたら、Trueflow、API 非公開だよね!ダメじゃん!
ええと、dtpwiki.jp ドメインの、dtpwiki.jp と blog.dtpwiki.jp 以外は、Mac mini(PPC/1.25GHz)で動いていまして、これが RAM が 256 MB のママ動かしているので、不必要に X 動いているので、CGI いっぱい動いちゃうとすぐスラッシングはじめて大変です(apache のプロセスもどれだけ絞っていいかわからん)。baidu とかやっつけろ、て言う気もするけれども、調整もせずに 1GB ぶっ込むことで対応してみることに。
ところで、購入ボタン押してから気づいたんだけれども、対応機種のところにM9686J/Aが書いていないのが非常に気になるな。
ヨドバシカメラに行ったら、駐車場が満杯で、しょうがないから、駅の表側に出て普通の駐車場に停めたんですけれども、その関係で、駅の表側を久しぶりに通ることになりましたが、アンジェラアキのピアノの代わりにアコースティックギターをもったような人がストリートミュージシャンとして歌っていました。
駅前だけにイーオンをイメージさせる人が歌うのもさもありなんと思ったけれどもよく考えると駅前留学は NOVA でしたっけ。
去年は某氏をひやかしに行ったけど、
ことしはむりやわー
あー普通に読み流すところだったけれども、
PS3をサーバにするLinuxディストリビューションが無償で提供開始:ニュース - CNET Japan [japan.cnet.com]
インテリジェントワークスは7月4日、ソニーのプレイステーション3(PS3)をサーバとして使用することを可能にするLinuxディストリビューション「HELIOS Linux」の無償提供を開始した。
HELIOS Linuxは、ドイツのHELIOS Softwareが、米Terra Soft SolutionsのPS3向けLinuxディストリビューション「Yellow Dog Linux」(YDL)を簡略化したもの。
インテリジェントワークスは、国内の HELIOS 販社の一つ(ヒューリンクスも取り扱っています)です。
Linux 用の HELIOS は使ってるよー
HELIOS は、元々 UNIX 互換 OS で動く AFP サービスで、20ユーザで数十万円するんです。OPI 用の HELIOS ImageServer を載っけると、もう 100 万円ぐらいになって涙目になります。
CentOS 4 で動かした HELIOS は、Mac OS X の AFP よりも安定しているくさいですが、PLAYSTATION 3 上の YellowDog Linux で動く HELIOS はどうなんでしょうか。インテリジェントワークスは、印刷業界向けに PS3 売るつもりなのかなー
とりあえず、いまだに AFP 2 しかサポートしない Windows Server の Service for Macintosh に比べると、長い名前のサポートとかがちゃんとしているから、検討してみたらどうでしょう。
# HDD 容量がネックかな。
株式会社インテリジェントワークス/HELIOS PlayStation 3 Linux インストール [www.intelligentworks.co.jp]
ちゃんと AFP サポートカーネルのビルド手順までフォローしてていいですね。僕、CentOS 4 でそれやるのにすごい苦労したぞ(この blog の中に書いてあるんじゃないかな)。
関連記事:
[231795]Intel ベースの Macintosh におけるプリンタおよびスキャナの問題(Photoshop CS3) [support.adobe.co.jp]
問題点 (Issue)
Intel ベースの Macintosh で、Adobe Photoshop CS3 からスキャンやプリントを行うことができません。
理由 (Reason)
PowerPC プロセッサ用のスキャナドライバおよびプリンタドライバは、Intel ベースの Macintosh では動作しません。
解決方法 (Solutions)
この問題を解決するには、以下の A. または B. のいずれか、または両方の操作を行います。
A. 最新のドライバをインストールします
Intel ベースの Macintosh に対応するスキャナおよびプリンタのドライバをインストールします。スキャナおよびプリンタドライバのアップデートについて、製造元へお問い合わせください。
B. Photoshop を Rosetta モードで起動します
我が家のMac は、PowerPC Only で、しかも1台は FedoraCore が入っているという Apple の人が泣きそうな使い方をしている有様ですから、Intel Mac ベースの話って伝聞でしかわからないのですけれども、これによると、Intel Mac 上の Mac OS X 上の Photoshop CS は、Intel ネイティブと、Rosettaモード(PowerPC 互換)を切り替えてつかえるのですね。こりゃベンチマークとかで便利だわ。
または、トラブルシューティングの一つとして、Rosetta モードにしてみそ?/やめてみそ? ていうことも新たに考えなくちゃいけないということですね。
夜食を買いに深夜まで営業の八百屋さんにいったら、レンタルビデオの使い古しのワゴンセール¥200があって、To Heart の VHS があったので買ってみたよ。
いまだに川澄川澄っていっているのはなんだかすごいなーて思った。
フォント vol.4 ~OpenTypeフォント~ (店長日記 印刷通販gr@phicブログ) [blog.graphic.jp]
TrueTypeフォントはPS(PostScript)プリンタでそのままプリントできないのでアウトライン化しなくちゃいけないし、
PageMaker あたりだとニョロニョロ出てましたよ、和文 TrueType フォントでさえも。この議論をするとき、アプリと和文 TrueType・欧文 TrueType のどっちの話なのか、っていつも謎ですよね。
PostScriptフォントはType1、OCF、CIDがあってMacintoshは使えるけどWindowsはダメでなどなど…。ややこしいですよね(>_<)
これ、ほんとうに、ややこしいですよね\(^o^)/
なにがややこしいかと言えば、Windows にも Type1 フォントがありました。Windows 版 Illustrator 7 付属の平成角ゴW5、平成明朝体W3 は CID フォントでしたし、CID フォントとしては、モリサワ ViewFont は有名ですよね、無かったことにしたいフォントっぽいですけど。でも、これあると OpenType フォント購入優待があったので販売終了直前に駆け込みで買った記憶があります。
「TrueType はアウトライン化で出力」「Windows には CID はダメ」などの「呪文」をつかえると楽っちゃー楽なんですけどね。
Windows における欧文 Type 1 はこの blog のどっかで書いた。Windows の OCF は昔話のできる方に譲ります(これは僕は知らない)。わかる人が僕をたたいてエントリを書けばいいさ。
下手にいらないことを知っていると何にも文章が書けなくなっちゃうっていう話でした。
こういうツッコミエントリのときに、よく自分の文章に抜けがあってやぶ蛇になるんですけれども、そういうときには、「詳しい人はツッコミしてください」ていうブルーシートを広げておくことが有効ですね。
[ネタです]
Windows Vista では、ファイルの中身がプレビューされたアイコンが付くファイル形式があったりしますけれども、Illustrator AI 形式はこんなんです。

▲これかっこいいっていうのとは違う次元だぞ
つうわけで、アイコンにプレビューをつけてみましょう。
~~~
まず、こんなのを描いてみました。

▲プリティサミーみたいです
次に、デスクトップへ普通に AI 形式で保存しましょう。

▲まあ普通だよね
この状態だと、いつもと同じ、プレビューじゃなくて、オレンジオレンジしたオレンジなソフトのアイコンになっているわけです。
▲アドビ的にはオレンジ=Illustratorとしたいらしいよ
ここからですが、おもむろにコマンドプロンプトを開きます。

▲スタートボタン(ウインドウズマーク)→アクセサリの中です
cd Desktop[Enter]
rename なんとか.ai *.pdf

▲すまん、おじさん、ren よりも rename 派なんだ
さすると、デスクトップのアイコンが、一瞬、PDF になった後、プレビューが表示されます。右下に PDF アイコンが出ていることから、PDF と認識されているようです。

▲PDFはプレビューをアイコンに表示するのです
ここで、もう一度名前を変更
rename なんとか.pdf *.ai

▲別に ren でやってもいいぜ
そうすると、アイコンにプレビューが表示されたまま、AI 形式と認識されるのでした。やったね!

▲アイコンの右下に AI となっているよね
~~~
レジストリいじると、最初からプレビュー表示できるようになるんじゃないかなー?
